Von unstrukturiert zu strukturiert: Wie Dokumentendaten nutzbar werden
80% aller Unternehmensdaten liegen in Dokumenten: PDFs, Scans, E-Mails. Diese Daten sind da – aber nicht nutzbar. Sie können sie nicht filtern, nicht aggregieren, nicht automatisch verarbeiten. Weil sie unstrukturiert sind.
Genau hier liegt das Problem vieler Datenprojekte. Die Systeme sind bereit, die Prozesse definiert – aber die Daten stecken in Dokumenten fest. Der Flaschenhals: Die Umwandlung von unstrukturiert zu strukturiert.
Unstrukturiert vs. Strukturiert: Was ist der Unterschied?
Bevor wir über Transformation sprechen, müssen wir verstehen, womit wir arbeiten. Der Unterschied zwischen unstrukturierten und strukturierten Daten ist fundamental – und erklärt, warum Dokumentenverarbeitung so komplex ist.
Unstrukturierte Daten
Ein PDF, ein Scan, eine E-Mail – das sind unstrukturierte Daten. Sie enthalten Informationen, aber in keinem standardisierten Format. Eine Rechnung von Lieferant A sieht anders aus als von Lieferant B. Die Rechnungsnummer steht mal oben rechts, mal in der Mitte. Der Betrag ist manchmal fett gedruckt, manchmal nicht.
Für Menschen kein Problem: Wir scannen das Dokument, finden die relevanten Zahlen, verstehen den Kontext. Für Maschinen ein Albtraum: Sie sehen nur Pixel oder bestenfalls einen langen Textstring ohne Struktur.
Strukturierte Daten
Strukturierte Daten haben ein definiertes Schema. Jedes Feld hat einen Namen, einen Typ, einen Platz. Eine Datenbanktabelle, ein JSON-Objekt, eine CSV-Datei – hier weiß das System genau: Spalte 1 ist die Rechnungsnummer, Spalte 2 das Datum, Spalte 3 der Betrag.
Mit strukturierten Daten können Sie arbeiten: filtern, sortieren, aggregieren, in andere Systeme importieren. Das ist das Ziel der Transformation.
Die Transformation: Vom Dokument zum Datensatz
Schauen wir uns an, was bei der Transformation konkret passiert. Nehmen wir eine simple Rechnung als Beispiel.
Vorher: Das Dokument
RECHNUNG
Mustermann GmbH Rechnungsnr.: RE-2024-0815Musterstraße 123 Datum: 15.01.202412345 Musterstadt
Position Beschreibung Menge Einzelpreis Gesamt------------------------------------------------------------------------1 Beratungsleistung 8 Std. 150,00 EUR 1.200,00 EUR2 Software-Lizenz 1 499,00 EUR 499,00 EUR------------------------------------------------------------------------ Netto: 1.699,00 EUR MwSt. 19%: 322,81 EUR Brutto: 2.021,81 EURNachher: Der Datensatz
{ "rechnungsnummer": "RE-2024-0815", "datum": "2024-01-15", "lieferant": { "name": "Mustermann GmbH", "adresse": "Musterstraße 123, 12345 Musterstadt" }, "positionen": [ { "beschreibung": "Beratungsleistung", "menge": 8, "einheit": "Std.", "einzelpreis": 150.00, "gesamt": 1200.00 }, { "beschreibung": "Software-Lizenz", "menge": 1, "einzelpreis": 499.00, "gesamt": 499.00 } ], "netto": 1699.00, "mwst_satz": 19, "mwst_betrag": 322.81, "brutto": 2021.81}Das ist Transformation: Aus einem Textblock wird ein strukturierter Datensatz mit klar definierten Feldern. Dieses JSON können Sie direkt in Ihre Buchhaltung importieren, mit anderen Rechnungen vergleichen, automatisch verbuchen.
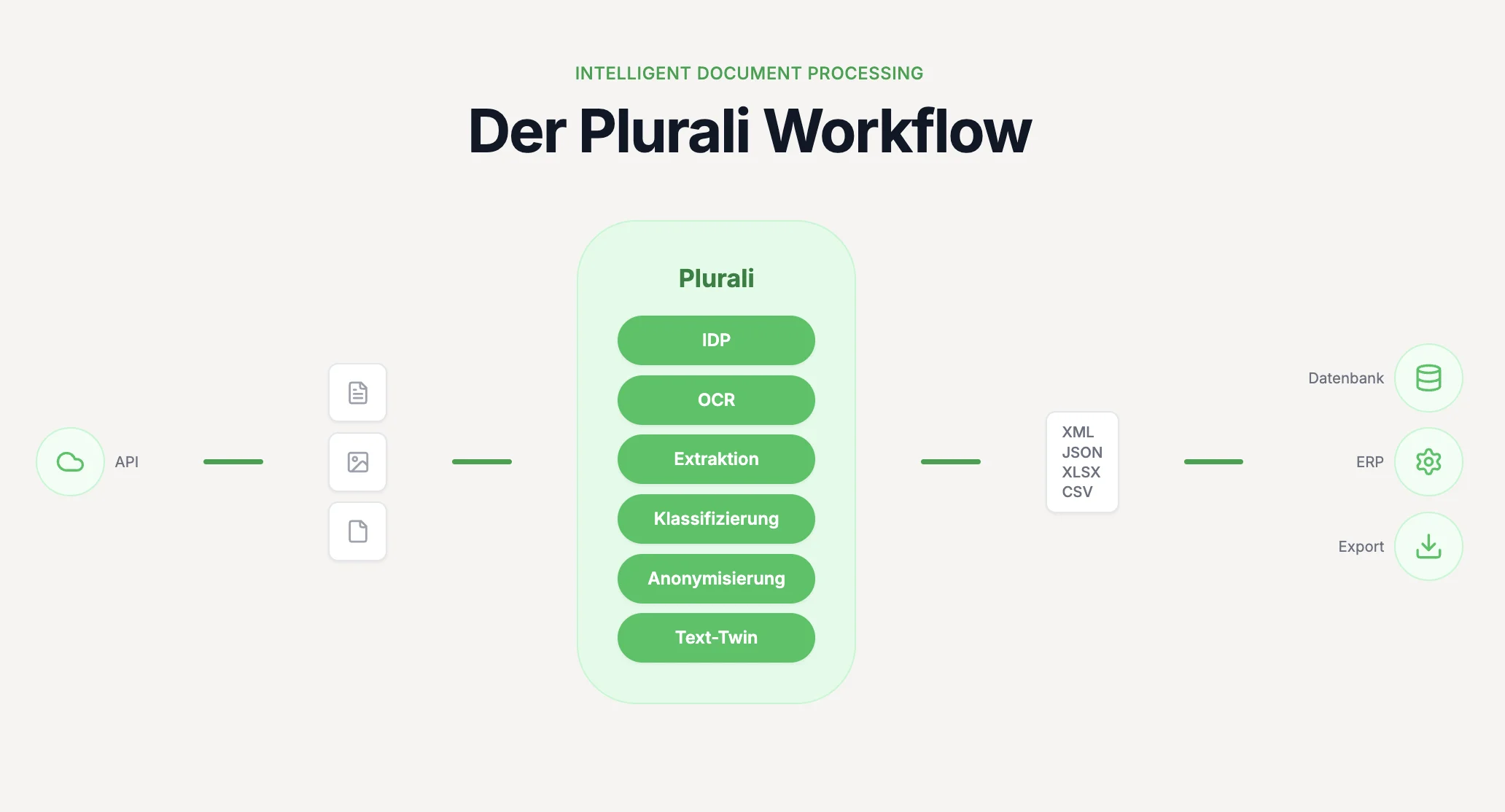
Wie funktioniert moderne Dokumenten-Transformation?
Die Transformation von Dokumenten zu Daten läuft in mehreren Schritten ab. Jeder Schritt baut auf dem vorherigen auf.
1. Texterkennung (OCR)
Bei gescannten Dokumenten oder Bildern muss zuerst der Text erkannt werden. OCR wandelt Pixel in Zeichen um. Das Ergebnis: ein langer String mit dem gesamten Textinhalt – aber noch ohne Struktur.
2. Layout-Analyse
Das System analysiert die räumliche Anordnung: Wo sind Überschriften? Wo Tabellen? Welche Textblöcke gehören zusammen? Diese Information ist entscheidend, um zu verstehen, dass 'RE-2024-0815' neben 'Rechnungsnr.:' steht und deshalb die Rechnungsnummer sein muss.
3. Semantische Extraktion
Hier kommt KI ins Spiel. Das System versteht, dass es sich um eine Rechnung handelt und welche Felder typischerweise vorkommen. Es erkennt Muster: Beträge mit EUR, Datumsformate, typische Feldbezeichnungen. Auch wenn eine Rechnung 'Invoice No.' statt 'Rechnungsnr.' schreibt – das System versteht den Kontext.
4. Validierung
Die extrahierten Daten werden geprüft: Stimmt die MwSt-Berechnung? Ist das Datum plausibel? Sind alle Pflichtfelder vorhanden? Fehler werden markiert, Konfidenzwerte berechnet.
5. Strukturierte Ausgabe
Am Ende steht ein sauberer Datensatz im gewünschten Format: JSON für APIs, CSV für Excel, XML für Legacy-Systeme – bereit für den Import in Ihre Zielsysteme.
Warum ist Datenstrukturierung so schwierig?
Bei strukturierten Datenquellen ist Transformation simpel: Feldmapping, Typkonvertierung, fertig. Bei Dokumenten ist es komplex, weil:
- Jeder Lieferant hat ein anderes Rechnungsformat
- Layouts ändern sich ohne Vorwarnung
- Scanqualität variiert stark
- Handschriftliche Notizen tauchen auf
- Mehrseitige Dokumente müssen zusammengeführt werden
- Sprachen und Währungen wechseln
Klassische regelbasierte Systeme scheitern an dieser Varianz. Sie funktionieren für Dokument A perfekt – und versagen komplett bei Dokument B. Moderne KI-basierte Lösungen lernen aus Beispielen und generalisieren.
Typische Einsatzszenarien
- Rechnungsverarbeitung: PDF-Rechnungen zu Buchungssätzen
- Vertragsanalyse: Vertragsdokumente zu strukturierten Metadaten
- Logistik: Lieferscheine und Frachtbriefe zu Wareneingangsdaten
- HR: Bewerbungsunterlagen zu Kandidatenprofilen
- Compliance: Dokumente zu auditierbaren Datensätzen
Fazit: Strukturierung ist der Schlüssel
Der Schlüssel zur Nutzung Ihrer Dokumentendaten liegt in der Strukturierung. Ihre Systeme sind bereit, Ihre Prozesse definiert – aber die Daten stecken in PDFs fest. Die Umwandlung von unstrukturierten Dokumenten zu strukturierten Daten erfordert spezialisierte Technologie.
Mit Plurali lösen Sie genau dieses Problem: Wir strukturieren Ihre Dokumente zu sauberen, nutzbaren Daten. Kein manuelles Abtippen, keine starren Templates. Die Daten aus Ihren Dokumenten – nutzbar gemacht.